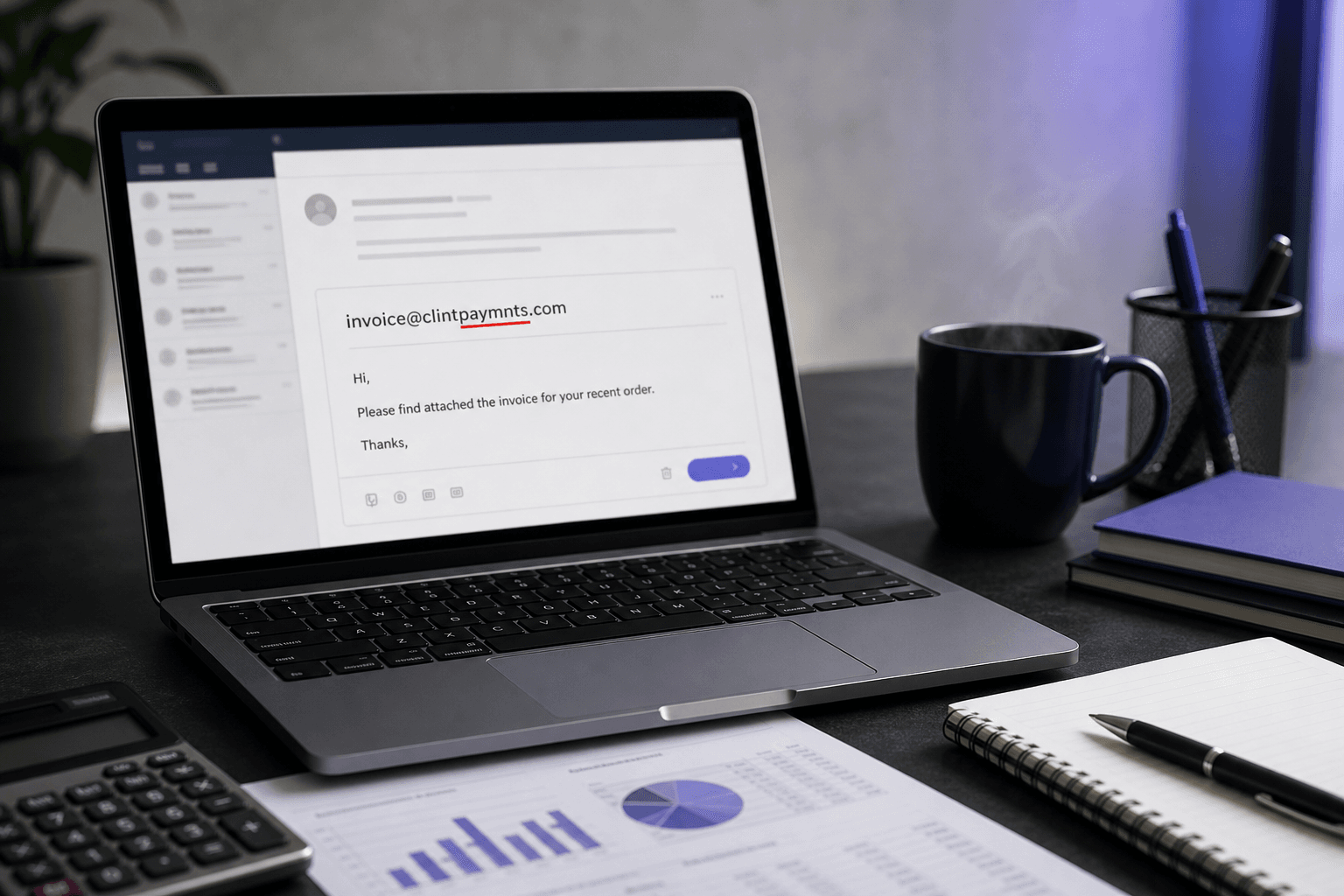
Un formulario de registro SaaS captura 500 nuevos usuarios el martes. La secuencia de incorporación se dispara el miércoles por la mañana. Para el jueves, 7 correos electrónicos han rebotado duramente — no desde direcciones falsas o desechables, sino desde "gmial.com", "yaho.com", "hotmial.com". Esos 7 usuarios escribieron rápidamente en el móvil, enviaron, y se fueron. Nunca verán el correo electrónico de activación. Algunos regresarán, culparán al producto, y se irán. El resto desaparece.
Cada error tipográfico en el correo electrónico en tu embudo de captura pertenece a una persona real que quería participar. Esto no es fraude. Esto no es tráfico de bots. Este es el silencioso 1–3% de cada lista que, según el análisis de ZeroBounce de más de 4 mil millones de direcciones, aparece como dominios con errores tipográficos — direcciones que pasan cada verificación regex, se ven perfectamente válidas, y silenciosamente rompen tu embudo antes de que llegue el primer correo electrónico de incorporación.

Tabla de Contenidos
- Por qué un Error Tipográfico en el Correo Electrónico es un Problema Diferente a una Dirección Falsa o Desechable
- El Costo Real de los Errores Tipográficos en Correos Electrónicos en Cinco Modelos de Negocio
- Los Seis Patrones de Errores Tipográficos que Representan la Mayoría de Direcciones Malas
- Métodos de Detección Comparados — Lo Que Realmente Detecta Errores Tipográficos en la Captura
- Un Flujo de Registro Resistente a Errores Tipográficos en Siete Decisiones
- Lo Que los Profesionales Realmente Preguntan sobre Errores Tipográficos en Correos Electrónicos
Por qué un Error Tipográfico en el Correo Electrónico es un Problema Diferente a una Dirección Falsa o Desechable
Comienza con la taxonomía, porque el resto del artículo depende de ella. Tres modos de fallo aparecen en cada formulario de registro, y se ven similares en tus registros de rebote mientras requieren respuestas completamente diferentes.
Las direcciones con errores tipográficos son usuarios legítimos con errores mecánicos de entrada: gmial.com, yaho.com, hotnail.com, outlok.com. La persona quiere el correo electrónico. Esperan el enlace de activación. Escribieron rápidamente, se perdieron por un carácter, y el formulario lo aceptó. Cada métrica en tu embudo los tratará como usuarios comprometidos y luego desaparecidos cuando en realidad son usuarios inaccesibles desde el principio.
Las direcciones desechables son legítimas en formato pero intencionales en evitación: mailinator.com, tempmail.io, guerrillamail.com. El usuario está activamente optando por no participar en una relación mientras aparenta estar optando por participar. Quieren la prueba, el contenido protegido, el código de descuento — no la mensajería del ciclo de vida. Un verificador dedicado de direcciones de correo electrónico desechables maneja esta categoría porque la lógica de detección es fundamentalmente una búsqueda de reputación de dominio, no un cálculo de proximidad.
Las direcciones inválidas o falsas son cadenas de basura, dominios inventados o envíos de bots: [email protected], [email protected]. Sin intención humana, sin señal recuperable. Rechaza y continúa.
Estos necesitan tratamiento diferente en el límite del registro. Una desechable debe ser bloqueada o degradada a un nivel de invitado. Un error tipográfico debe ser marcado con un aviso de corrección de un clic. Una falsificación debe ser rechazada con un error genérico. Tratarlos como una única categoría "correo electrónico malo" produce uno de dos modos de fallo: o agregas fricción a usuarios recuperables bloqueándolos duramente, o aceptas todo y absorbes el daño de rebote aguas abajo. Ambos son caros.
La razón por la que la validación regex no puede detectar errores tipográficos es estructural, no específica de la implementación. RFC 5321 y RFC 5322 definen la sintaxis de una dirección de correo electrónico — caracteres permitidos, reglas de entrecomillado, formato de dominio, límites de longitud. La cadena "[email protected]" es completamente conforme a RFC. El buzón no existe; el dominio está registrado a un ocupante de typo-squatter; el usuario nunca recibirá un solo byte de tus servidores. Pero la cadena es válida. Regex funciona en caracteres, no en resolución de DNS o proximidad de dominio. Este es un límite de categoría del reconocimiento de patrones, no algo que puedas arreglar con un patrón mejor.
Una dirección con error tipográfico es completamente conforme a RFC, sintácticamente perfecta y estructuralmente indistinguible de una real — que es exactamente por qué tu capa de validación la está dejando pasar.
El volumen oculto es mayor de lo que la mayoría de los equipos estiman. El conjunto de datos de 4 mil millones de direcciones de ZeroBounce coloca dominios con errores tipográficos en el rango de 1–3% de capturas típicas de formularios web. La investigación de dominios con errores tipográficos de Kickbox señala que las audiencias con un fuerte enfoque móvil se sesgan hacia el extremo superior de ese rango porque la entrada en pantalla táctil produce tasas de error a nivel de carácter más altas que los teclados físicos. Para un SaaS que realiza 10,000 registros por mes a una tasa de error tipográfico del 1.5%, eso son 150 usuarios cada mes que se auto-descalificaron de cada correo electrónico del ciclo de vida que envías — activación, educación de características, recordatorios de facturación, recuperación.
Esos 150 usuarios fluyen a través de tres canales de costo aguas abajo simultáneamente. Las secuencias de incorporación se disparan al vacío, arrastrando la conversión de prueba a pagado. El correo transaccional — restablecimiento de contraseña, recibos, códigos de dos factores — nunca llega, generando tickets de soporte a $5–15 cada uno. Las campañas de marketing acumulan rebotes duros que erosionan tu reputación de remitente en todo el dominio, no solo para las direcciones con errores tipográficos. La matriz de costos en la siguiente sección cuantifica cada canal para cinco modelos de negocio comunes.
El Costo Real de los Errores Tipográficos en Correos Electrónicos en Cinco Modelos de Negocio
La misma tasa de error tipográfico del 1–3% produce un daño en dólares dramáticamente diferente dependiendo de lo que el correo electrónico realmente hace en tu negocio. Un cliente potencial B2B con error tipográfico y un cierre de e-commerce con error tipográfico fallan de diferentes maneras, en diferentes líneas de tiempo, contra diferentes líneas de base de ingresos.
| Modelo de Negocio | Función Principal de Correo Perdida | Impacto de Tasa de Errores Tipográficos | Efecto Compuesto |
|---|---|---|---|
| Prueba gratuita de SaaS | Activación + secuencia de incorporación | 1–2% nunca inician la prueba | Pérdida de mejora de incorporación del 15–25% |
| Cierre de e-commerce | Confirmación de pedido + envío | 1–3% disparan tickets de soporte | $5–15 por "¿dónde está mi pedido?" |
| Boletín / contenido | Bienvenida + campañas en curso | 1–3% nunca confirman compromiso | El rebote se acerca a la zona de peligro del 2% |
| Generación de clientes potenciales B2B | Nutrición de cliente potencial + entrega de ventas | 0.5–1.5% (fuerte en escritorio) | MQL perdido = CAC completo desperdiciado |
| Aplicación de consumidor con enfoque móvil | Verificación de cuenta + re-participación | 2–3%+ (sesgo móvil) | Agrava la retención móvil baja |
Fuentes de tasa de errores tipográficos: análisis de 4 mil millones de direcciones de ZeroBounce e investigación de dominios con errores tipográficos de Kickbox. Cifras de mejora de incorporación del Informe de Métricas SaaS 2023 de Totango. Umbrales de rebote de puntos de referencia de entregabilidad de Mailchimp y Prácticas Comunes Mejores de Remitentes de M3AAWG. Tasas de error móvil de investigación de entrada de texto MobileHCI de Azenkot y Zhai.
SaaS sufre el impacto más alto en dólares por error tipográfico porque el costo se agrava en todo el ciclo de vida del cliente. Recorre las matemáticas. Los puntos de referencia de Totango colocan la mejora de una secuencia de correo electrónico de incorporación estructurada en 15–25% sobre ninguna secuencia. Un usuario con error tipográfico recibe cero correos electrónicos de incorporación y revierte a la conversión de línea de base. Para un plan de $50/mes con permanencia promedio de 12 meses, un delta de conversión de 20 puntos en cada registro perdido representa aproximadamente $120 en ingresos esperados por registro con error tipográfico. En 10,000 registros por mes y una tasa de error tipográfico del 1.5%, eso son 150 usuarios × $120 = aproximadamente $18,000 por mes en ingresos esperados silenciosamente perdidos — antes de contar los efectos de referencia, expansión o boca a boca.
Cada punto porcentual de errores tipográficos no detectados en tu formulario de registro es un punto porcentual de tu inversión en incorporación que se dispara al vacío.
E-commerce paga en carga de soporte, no solo correo perdido. Los datos de punto de referencia de servicio al cliente de Zendesk colocan los problemas de autenticación e "No recibí mi correo electrónico" entre las principales categorías de tickets entrantes, frecuentemente representando el 15–30% del volumen total. Una parte significativa se remonta al cierre con error tipográfico, no a la falla de entregabilidad del lado del remitente. El cliente escribió gmial.com, la confirmación del pedido rebotó duramente, el cliente asume que el pedido falló, y el ticket se alinea a $5–15 para resolverse manualmente.
Los remitentes de boletines enfrentan cascadas de reputación. Cuando el 1–3% de nuevos registros rebota duramente, aceleras hacia el techo de rebote por campaña que Mailchimp marca como la zona de peligro de entregabilidad. El daño no está aislado a las direcciones con errores tipográficos — los ISP aplican filtrado a todo tu dominio de envío una vez que las tasas de rebote se sostienen por encima del 2%. Una cohorte de captura mala puede suprimir la colocación de bandeja de entrada legítima para las próximas tres campañas.
El ROI de correo electrónico reportado por DMA de $35–$42 por $1 gastado (Rastreador de Correo Electrónico del Vendedor de DMA) amplifica el cálculo de costo. Incluso pequeños porcentajes de correos electrónicos no entregados se multiplican contra esa relación de apalancamiento. Una tasa de error tipográfico del 1.5% no es una pérdida de ingresos del 1.5% — es el 1.5% de tu inversión en envío produciendo cero salida mientras el 98.5% restante produce el ROI publicado. La asimetría es lo que hace que los errores tipográficos valgan la pena corregir en relación con su tamaño aparente.
Los Seis Patrones de Errores Tipográficos que Representan la Mayoría de Direcciones Malas
Los errores tipográficos no son aleatorios. Se agrupan en un puñado de patrones mecánicos impulsados por el diseño del teclado, el comportamiento de autocorrección móvil y atajos cognitivos predecibles. Conocer el mecanismo detrás de cada patrón te dice qué es determinísticamente correctable frente a qué necesita confirmación del usuario.
- Errores tipográficos de proximidad a nivel de dominio (gmial, yhoo, hotnail). Estos siguen la adyacencia del teclado QWERTY — "i" y "a" se sientan uno al lado del otro en la fila de inicio, el dedo índice se resbala, el formulario acepta el resultado. ZeroBounce identifica estos como la categoría de error tipográfico más grande en su conjunto de datos de 4 mil millones de direcciones. También son los más recuperables: la distancia de Levenshtein al dominio correcto es 1, la búsqueda difusa contra una lista corta de proveedores principales los atrapa con alta precisión.
- Confusión de TLD (.co vs .com, .net vs .com, .om vs .com). Impulsado por teclados móviles donde ".com" es una tecla de acceso directo única que puede ser perdida, y por usuarios en mercados con TLD de código de país activo (.co.uk, .com.au) que se abren paso en una combinación incorrecta. Particularmente dañino porque ".co" es en sí mismo un TLD válido asignado a Colombia. Las verificaciones de existencia de dominio pasan limpiamente. El buzón casi ciertamente no existe.
- Intercambios de subdominio y proveedor (outlook.com ↔ live.com, icloud ↔ icould, msn ↔ mns). Los usuarios olvidan qué dominio de Microsoft o Apple-era su cuenta usa, especialmente después de migraciones. Mayor prevalencia en demografía de usuarios más antiguos donde el registro original sucedió en un proveedor heredado. La búsqueda difusa contra un registro de dominio con error tipográfico los atrapa; regex no.
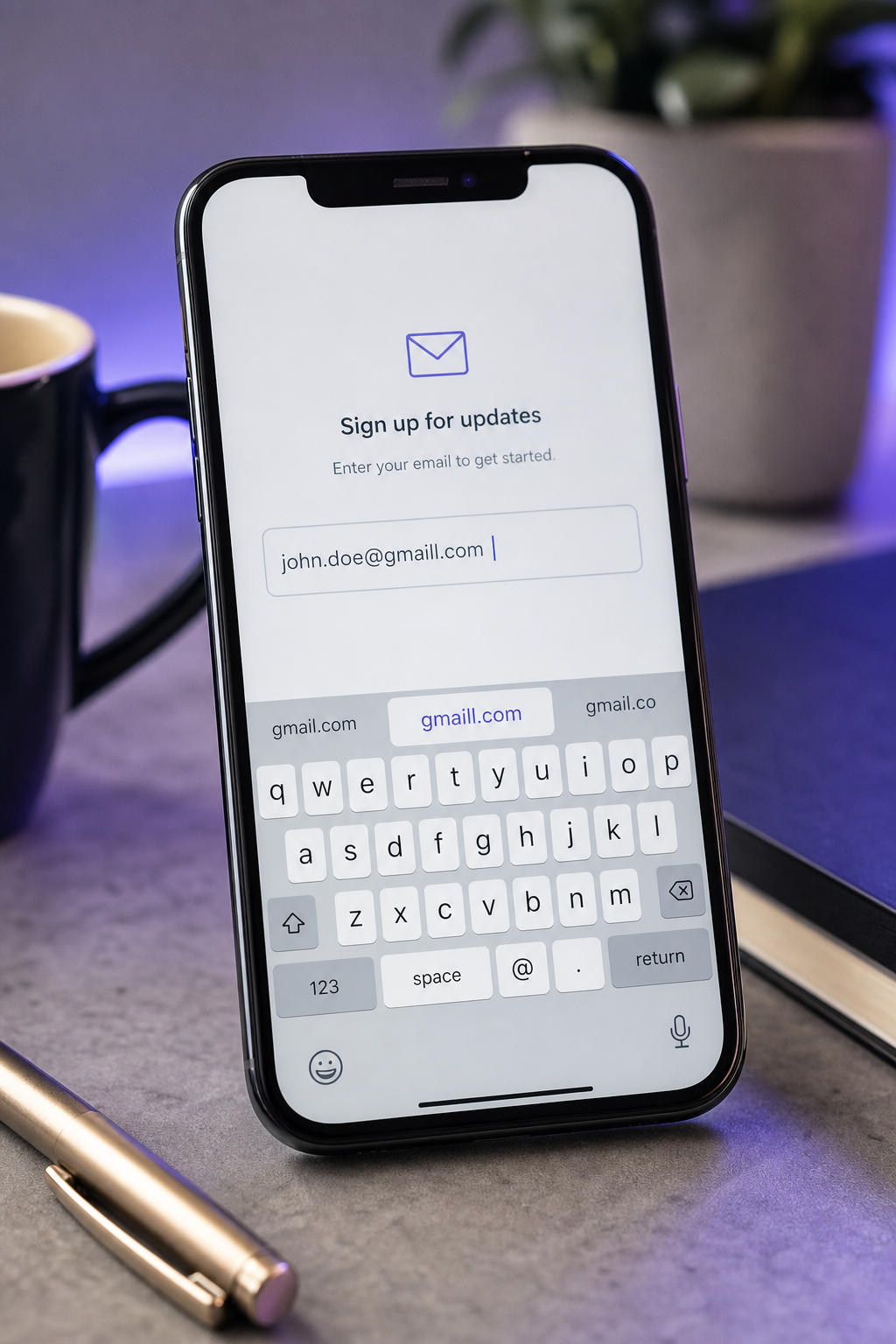
- Caracteres duplicados o descartados (aaccount, coom, gmaill, hotmai). Artefactos de autorrelleno de pantalla táctil. La investigación de entrada de texto de Azenkot y Zhai documenta sistemáticamente tasas de error a nivel de carácter más altas en pantallas táctiles que en teclados de hardware, particularmente para cadenas que los usuarios no verifican visualmente antes de enviar. Los campos de correo electrónico son de alto riesgo porque son largos, sin diccionario y visualmente densos.
- Autocorrección móvil anula. El texto predictivo silenciosamente "corrige" fragmentos de correo electrónico válidos en palabras comunes del diccionario ("gmail" → "gail", "outlook" → "outlooks"). La solución es estructural en lugar de detectiva: los campos de entrada deben declarar
type="email"yautocomplete="email"para desactivar autocorrect a nivel del SO. La guía de diseño de formularios del Nielsen Norman Group trata esto como práctica de línea de base para cualquier campo de alto riesgo de error. - Errores de espacio en blanco y puntuación (espacio final, coma-por-punto, @ doble). A menudo invisible para el usuario porque el campo de formulario visualmente recorta la pantalla, ocultando el problema hasta que SMTP rechaza la dirección. La lógica de corte y normalización en la captura elimina el subconjunto recuperable; el resto necesita validación explícita contra la gramática de dirección.
De estos seis patrones, tres son determinísticamente corregibles a partir de la cadena de dirección sola (proximidad, TLD, caracteres duplicados), dos requieren confirmación del usuario porque son ambiguas (intercambios de subdominio, anulaciones de autocorrección), y uno es prevenido en la capa de entrada antes de que se ejecute cualquier validación (espacio en blanco). El mapa de remediación es importante porque establece el contrato de UX: qué patrones justifican normalización silenciosa, qué justifican un aviso "¿Quisiste decir?", y qué justifican bloqueo con un mensaje de error.
Métodos de Detección Comparados — Lo Que Realmente Detecta Errores Tipográficos en la Captura
La mayoría de los equipos ya tienen algo validando su campo de correo electrónico. La pregunta es si lo que tienen realmente atrapa la categoría de error tipográfico en lugar de la categoría de sintaxis. Los cinco métodos a continuación cubren el espacio de opciones realista.
| Método | Atrapa Errores Tipográficos | Tiempo Real | Fricción Agregada | Impacto de Lista |
|---|---|---|---|---|
| Verificación de sintaxis Regex / RFC | No | Sí | Ninguno | Ninguno |
| Confirmación de doble opción | Después de rebote | No (async) | Alto | Reducción del 20–40% |
| Coincidencia difusa del lado del cliente | Parcial | Sí | Bajo | Mínimo |
| Verificación de registro MX de dominio | No | Sí | Ninguno | Bajo |
| API de Verificación en Tiempo Real | Sí | Sí (sub-500ms) | Mínimo | Mínimo |
Cifra de reducción de doble opción: estudio de opción única vs doble de GetResponse. Latencia de API en tiempo real: documentación de API de NeverBounce. Arquitectura de validación de tres capas (sintaxis → MX → buzón): documentación de API de ZeroBounce.
Regex es necesario pero insuficiente. Aplica RFC 5321 y 5322 limpiamente, filtra cadenas obviamente formateadas incorrectamente, y se ejecuta en tiempo cero en el cliente. Cada dirección con error tipográfico discutida anteriormente pasa regex sin vacilar. Trata regex como tu primer filtro, nunca como tu único.
La doble opción es la "solución" más popular y la más cara. El estudio de GetResponse encontró que las listas de doble opción eran 20–40% más pequeñas que las listas de opción única — y los usuarios con error tipográfico están matemáticamente garantizados de estar en el 20–40% faltante porque no pueden recibir el correo electrónico de confirmación por definición. El mecanismo está al revés: los correos de confirmación diagnostican el problema de error tipográfico solo después de que el usuario ya está perdido. Descubres el error tipográfico cuando el mensaje de confirmación mismo rebota duramente, momento en el cual el usuario ha cerrado la pestaña. La doble opción todavía tiene valor para permiso y filtrado de compromiso. No es, en ningún sentido significativo, una capa de detección de errores tipográficos.

La coincidencia difusa del lado del cliente ("¿Quisiste decir gmail.com?") es buena UX, frágil como infraestructura. Requiere mantener un diccionario de dominio con error tipográfico, manejar dominios internacionalizados, y evitar el modo de fallo documentado por Baymard Institute en el cual TLD legítimos de código de país o corporativos se marcan como errores tipográficos. El diccionario envejece. Nuevos patrones de digitación errónea emergen. Útil como capa de UI encima de una llamada de verificación real. No un sustituto para una.
Las verificaciones de registros MX descartan dominios inexistentes pero pierden casos de error tipográfico de dominio real. "gmial.com" es un dominio registrado que resuelve MX — eso es exactamente por qué es una trampa de error tipográfico de larga duración. El ocupante ilegal quiere el tráfico. Las verificaciones MX atrapan dominios fabricados; no atrapan la categoría de error tipográfico de la que habla este artículo. La verificación es barata y vale la pena ejecutar, pero no confundas pasarla por ser una dirección real.
Los API de verificación en tiempo real combinan las cuatro capas. La arquitectura estándar documentada por ZeroBounce y NeverBounce ejecuta sintaxis → MX → sonda a nivel de buzón → bandera de dominio con error tipográfico → bandera de dominio desechable en una única llamada sub-500ms. La salida no es un pase/fallo binario; es un veredicto clasificado en el que el flujo de registro puede ramificarse diferentemente por categoría. Una llamada de validación de dirección de correo electrónico en tiempo real devuelve estas señales como códigos de resultado separados, que es lo que te permite sugerir para errores tipográficos, bloquear para desechables, y rechazar para inválidos sin escribir cinco validadores independientes.
La latencia no es una objeción. Los tiempos de respuesta publicados de NeverBounce de 100–500ms están por debajo del umbral de percepción para retraso de UI, especialmente cuando la llamada se dispara en desenfoque de campo en lugar de en envío. Los usuarios ya han movido su atención al siguiente campo; la sugerencia aparece cuando miran hacia atrás.
Un Flujo de Registro Resistente a Errores Tipográficos en Siete Decisiones
La arquitectura a continuación es táctica, no teórica. Cada elemento es una decisión que el equipo toma una vez y codifica en la ruta de código de registro. El razonamiento es más importante que la sintaxis específica — adapta a tu pila.
- Valida en desenfoque, no solo en envío. Ejecuta la llamada de verificación cuando el campo de correo electrónico pierde el enfoque para que el aviso de sugerencia aparezca antes de que el usuario se haya comprometido mentalmente con el siguiente campo. La investigación de formularios del Nielsen Norman Group muestra que la validación en línea supera la validación en tiempo de envío para recuperación de errores porque el usuario aún está orientado al campo que acaba de dejar. Los errores en tiempo de envío requieren re-orientación y se sienten como castigo.
- Usa una respuesta de API clasificada por veredicto, no un booleano. La respuesta debe separar banderas de error tipográfico, desechable, cuenta de rol e inválida-buzón para que cada una pueda disparar una UI diferente. Las respuestas "is_valid" booleanas te fuerzan a elegir un tratamiento para cinco problemas diferentes, que es cómo los equipos terminan bloqueando usuarios recuperables. Los API de vendedores estructuran las respuestas de esta manera por una razón.
- Sugiere, no corrijas automáticamente. Para banderas de error tipográfico, renderiza "¿Quisiste decir [email protected]?" como una aceptación de un clic. La corrección automática silenciosa viola la confianza del usuario — la investigación de formularios de e-commerce de Baymard muestra que los usuarios abandonan cuando atrapan un campo cambiando bajo ellos — y rompe para casos límites legítimos como dominios corporativos que se ven como errores tipográficos pero no lo son.
- Bloquea desechables por separado de errores tipográficos. Una señal desechable justifica un bloqueo duro o una degradación a una cuenta de nivel de invitado con características limitadas. Una señal de error tipográfico justifica una sugerencia suave con una corrección de un clic. Tratar a ambas igual penaliza usuarios recuperables mientras bajo-protege contra abuso de pruebas. El costo de ramificación es un condicional adicional.
- Desactiva autocorrect en la capa de entrada. Usa
<input type="email" autocomplete="email" autocorrect="off" spellcheck="false">. Esto pre-empta el patrón de anulación de autocorrección antes de que cualquier validación se ejecute. Es un cambio de cinco atributos que elimina una clase de error tipográfico completa. - Establece umbrales de rebote duro e instrumentalos. M3AAWG y Mailchimp ambos aconsejan que los rebotes duros agregados se mantengan por debajo del 1% por campaña, con 2% siendo la zona de peligro de entregabilidad. Alerta en tasas de rebote de cohorte de registro por encima del 1.5% — no solo tasas de toda la campaña. El rebote a nivel de cohorte es un indicador inicial de que tu validación del lado de captura está fallando para una fuente específica, que los promedios de toda la campaña diluirán.
- Registra patrones de error tipográfico y devuélvelos. Rastrea qué dominios tus usuarios escriben más frecuentemente de forma incorrecta. Si tu audiencia produce un patrón recurrente de "yaho.com" o ".cm", ahora sabes dónde endurecer la lógica de sugerencia. Esto cierra el bucle entre detección en tiempo de captura e insight de higiene de lista en curso — y te permite medir el delta real de cada cambio de validación en lugar de adivinar.

El flujo en su conjunto requiere una integración de API y un puñado de decisiones de UI. El beneficio compuesto es que cada sistema aguas abajo — incorporación, facturación, soporte, marketing — opera en direcciones que ya han pasado los filtros de error tipográfico, desechable e inválido en el límite. Dejas de diagnosticar problemas de calidad de lista en paneles y comienzas a prevenirlos en el formulario.
Lo Que los Profesionales Realmente Preguntan sobre Errores Tipográficos en Correos Electrónicos
- ¿No está un correo electrónico de confirmación ya atrapando los errores tipográficos? No — los diagnostica, no los atrapa. La comparación de opción única vs doble de GetResponse encontró que el 20–40% de los usuarios nunca confirman, y los usuarios con error tipográfico están matemáticamente garantizados de estar en el grupo faltante porque no pueden recibir la confirmación por definición. Aprendes sobre el error tipográfico solo cuando el mensaje de confirmación mismo rebota duramente, momento en el cual el usuario ha cerrado la pestaña y se ha ido. La validación de dirección de correo electrónico en tiempo real del lado de captura expone el error tipográfico mientras el usuario aún está en el formulario y puede arreglarlo con un clic. Los correos de confirmación siguen siendo valiosos para filtrado de permiso y compromiso — prueban que el usuario realmente quería recibir tu correo. No son, mecánicamente, un sustituto para detección de error tipográfico en captura. Las dos capas hacen trabajos diferentes y deben coexistir.
- Si auto-corrijo "gmial" a "gmail", ¿estoy anulando la intención del usuario? Estás corrigiendo un error mecánico de entrada, no una opción intencional — pero solo si confirmas con el usuario. La investigación de formularios de e-commerce de Baymard Institute muestra que las correcciones silenciosas dañan la confianza y rompen casos límites, particularmente dominios corporativos y TLD regionales que se ven como errores tipográficos pero no lo son (.co Colombia, .om Omán). El patrón defendible es una sugerencia de un clic: "¿Quisiste decir [email protected]? [Sí, usar esto] [No, mantener el mío]." Esto preserva la agencia del usuario mientras hace la corrección sin fricción. El usuario retiene la decisión final, la dirección con error tipográfico se recupera en el 95%+ de casos donde la sugerencia es correcta, y el raro caso límite legítimo tiene una ruta de anulación limpia. Las reescrituras silenciosas optimizan por la métrica incorrecta y producen una experiencia peor para la cola larga.
- ¿Cuál es la diferencia entre una dirección con error tipográfico y una dirección desechable — y por qué importa? Un error tipográfico es un usuario legítimo con un error mecánico; desechable es un usuario evitando activamente una relación. Las señales se superponen aguas abajo — ambas producen rebotes, ambas reducen la calidad de la lista, ambas perjudican la entregabilidad — pero la respuesta en la captura debe diferir. Los errores tipográficos obtienen un aviso de sugerencia porque el usuario quiere participar. Los desechables se bloquean o se degradan porque el usuario está optando por no participar mientras aparenta estar optando por participar. Un API en tiempo real que los marca por separado te permite encaminar cada uno apropiadamente sin escribir dos validadores paralelos. Tratarlos idénticamente ya sea sobre-bloquea usuarios recuperables (si rechazas duramente errores tipográficos junto con desechables) o bajo-protege contra abuso de pruebas (si solo advieres suavemente desechables junto con errores tipográficos). Un verificador dedicado de direcciones de correo electrónico desechables maneja la capa de detección específica de desechable; una capa de sugerencia de error tipográfico se sienta encima de ella.
- ¿Cuántos de mis registros realmente tienen errores tipográficos en este momento? Los datos de la industria convergen en 0.5–2% para audiencias B2B con fuerte presencia en escritorio y 2–3%+ para aplicaciones de consumidor con enfoque móvil, con el conjunto de datos de 4 mil millones de direcciones de ZeroBounce y la investigación de dominio con error tipográfico de Kickbox como las dos fuentes más citadas. Para medir tu propia línea de base en lugar de adivinar: extrae los últimos 90 días de registros, cruza referencias contra el registro de rebote duro de tu ESP, y aísla los rebotes donde el dominio está a un carácter de distancia de Levenshtein de un proveedor importante (gmail, yahoo, hotmail, outlook, icloud, aol). Ese subconjunto es tu tasa de error tipográfico actual. Ejecuta la misma consulta nuevamente 30 días después de desplegar validación en tiempo real para medir el delta limpiamente. Los números antes/después son los únicos que importan para justificar la integración internamente.
- ¿Puedo construir detección de error tipográfico yo mismo sin un API? Parcialmente. Un script de coincidencia difusa del lado del cliente contra una lista codificada de dominios comunes con errores tipográficos (gmial.com, yaho.com, hotnail.com, outlok.com, icould.com) atrapa el 60–70% superior de casos a bajo costo — distancia de Levenshtein ≤ 2 contra una lista de 20 proveedores principales cubre una parte sorprendente del volumen. Los casos restantes requieren infraestructura: manejo de confusión de TLD, detección de intercambio de subdominio, sondas de no-existencia de buzón a nivel de SMTP, y un registro de dominio con error tipográfico continuamente actualizado a medida que emergen nuevos patrones. El umbral de construir vs comprar es usualmente si tu equipo quiere ser dueño del mantenimiento de diccionario, infraestructura de verificación MX, y sondas de buzón SMTP en perpetuidad. Para la mayoría de los equipos, la ruta de API es más barata que la sobrecarga de mantenimiento, y la ganancia de cobertura marginal en los patrones de cola larga es donde vive el ingreso real — no en el 60% superior que cualquier script decente maneja el primer día.