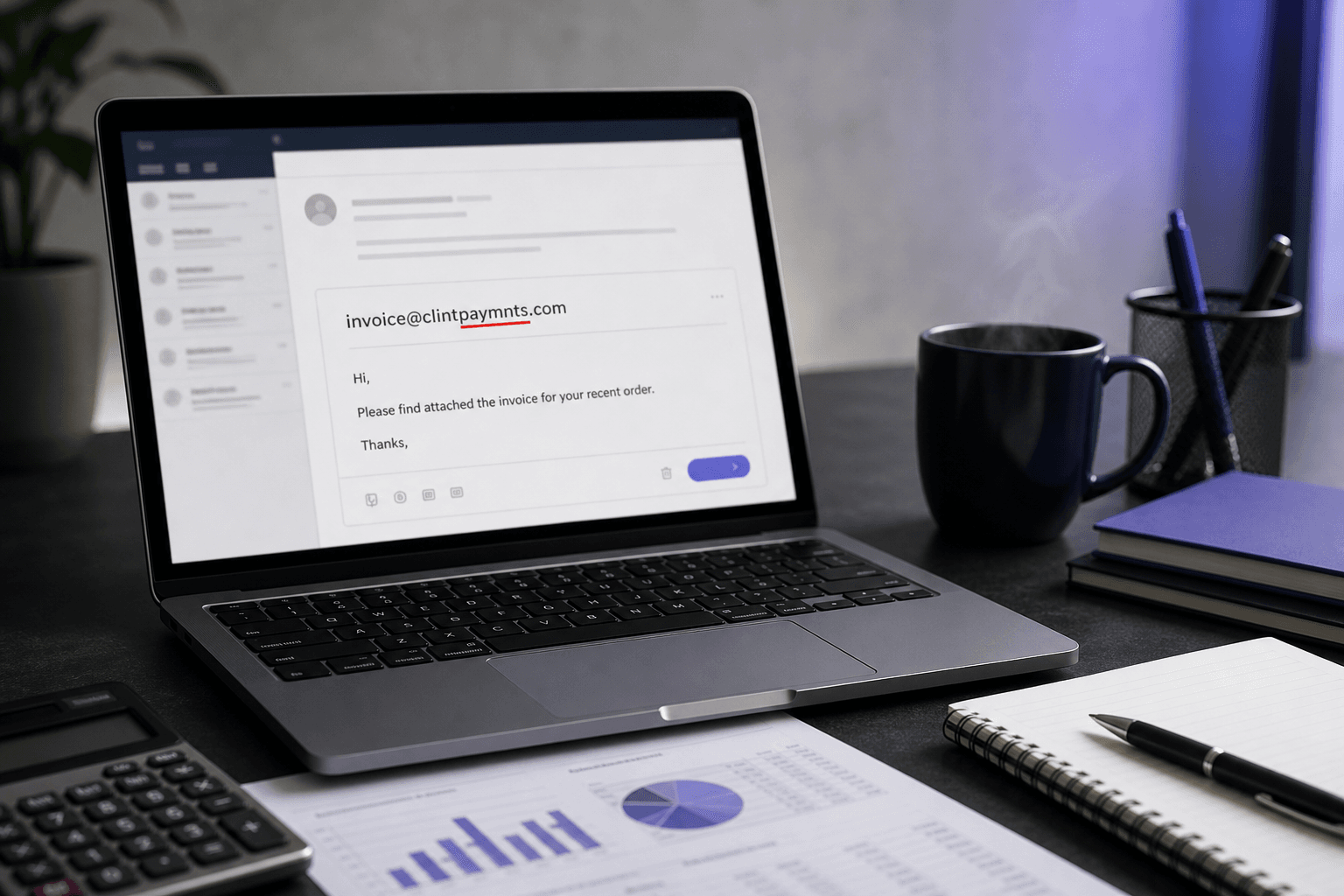
Um formulário de inscrição de SaaS captura 500 novos usuários na terça-feira. A sequência de onboarding dispara na quarta-feira de manhã. Até quinta-feira, 7 emails sofreram rejeição total — não de endereços falsos ou descartáveis, mas de "gmial.com", "yaho.com", "hotmial.com". Esses 7 usuários digitaram rapidamente em dispositivos móveis, clicaram em enviar e continuaram. Nunca verão o email de ativação. Alguns voltarão, culparão o produto e cancelarão a assinatura. O resto desaparece.
Todo erro de digitação de email no seu funil de captura pertence a uma pessoa real que queria entrar. Não é fraude. Não é tráfego de bot. É o silencioso 1–3% de toda lista que, de acordo com a análise da ZeroBounce de mais de 4 bilhões de endereços, aparece como domínios com erros de digitação — endereços que passam em todas as verificações regex, parecem perfeitamente válidos e silenciosamente quebram seu funil antes do primeiro email de onboarding chegar.

Índice
- Por Que Um Erro de Digitação de Email É um Problema Diferente de Um Endereço Falso ou Descartável
- O Custo Real dos Erros de Digitação de Email Em Cinco Modelos de Negócio
- Os Seis Padrões de Erros de Digitação Que Explicam a Maioria dos Endereços Ruins
- Métodos de Detecção Comparados — O Que Realmente Detecta Erros de Digitação na Captura
- Um Fluxo de Registro Resistente a Erros de Digitação Em Sete Decisões
- O Que Os Praticantes Realmente Perguntam Sobre Erros de Digitação de Email
Por Que Um Erro de Digitação de Email É um Problema Diferente de Um Endereço Falso ou Descartável
Comece com a taxonomia, porque o resto do artigo depende dela. Três modos de falha aparecem em todos os formulários de inscrição, e parecem semelhantes nos seus logs de rejeição enquanto exigem respostas completamente diferentes.
Endereços com erros de digitação são usuários legítimos com erros de entrada mecânicos: gmial.com, yaho.com, hotnail.com, outlok.com. A pessoa quer o email. Ela espera o link de ativação. Digitou rapidamente, perdeu um caractere, e o formulário aceitou. Cada métrica em seu funil os tratará como usuários engajados-e-desaparecidos quando na verdade são usuários inacessíveis-desde-o-início.
Endereços descartáveis são legítimos em formato mas intencionais em evasão: mailinator.com, tempmail.io, guerrillamail.com. O usuário está optando ativamente por sair de um relacionamento enquanto aparenta optar por entrar. Quer o período de teste, o conteúdo restrito, o código de desconto — não as mensagens do ciclo de vida. Um verificador dedicado de endereço de email descartável trata esta categoria porque a lógica de detecção é fundamentalmente uma pesquisa de reputação de domínio, não um cálculo de proximidade.
Endereços inválidos ou falsos são strings de lixo, domínios inventados ou submissões de bot: [email protected], [email protected]. Nenhuma intenção humana, nenhum sinal recuperável. Rejeite e continue.
Estes precisam de tratamento diferente no limite de registro. Um descartável deve ser bloqueado ou reduzido a um nível de convidado. Um erro de digitação deve ser sinalizado com um prompt de correção de um clique. Um falso deve ser rejeitado com uma mensagem de erro genérica. Tratá-los como uma única categoria de "email ruim" produz um dos dois modos de falha: ou você adiciona atrito aos usuários recuperáveis bloqueando-os, ou aceita tudo e absorve o dano de rejeição a jusante. Ambos são caros.
A razão pela qual a validação regex não consegue detectar erros de digitação é estrutural, não específica da implementação. RFC 5321 e RFC 5322 definem a sintaxe de um endereço de email — caracteres permitidos, regras de citação, formato de domínio, limites de comprimento. A string "[email protected]" é totalmente compatível com RFC. A caixa de correio não existe; o domínio é registrado para um squatter de erros de digitação; o usuário nunca receberá um único byte dos seus servidores. Mas a string é válida. Regex opera em caracteres, não em resolução de DNS ou proximidade de domínio. Este é um limite de categoria da correspondência de padrões, não algo que você possa corrigir com um padrão melhor.
Um endereço com erro de digitação é totalmente compatível com RFC, sintaticamente perfeito e estruturalmente indistinguível de um real — que é exatamente por que sua camada de validação está deixando passar.
O volume oculto é maior do que a maioria das equipes estima. O conjunto de dados de 4 bilhões de endereços da ZeroBounce coloca domínios com erros de digitação na faixa de 1–3% de capturas típicas de formulário web. A pesquisa de domínio com erro de digitação da Kickbox observa que públicos com peso em dispositivos móveis tendem ao extremo superior dessa faixa porque a entrada de tela sensível ao toque produz taxas de erro de caractere mais altas do que teclados físicos. Para um SaaS fazendo 10.000 inscrições por mês a uma taxa de 1,5% de erro de digitação, são 150 usuários por mês que se auto-desqualificaram de todos os emails do ciclo de vida que você envia — ativação, educação de recursos, lembretes de cobrança, win-back.
Esses 150 usuários fluem por três canais de custo a jusante simultaneamente. Sequências de onboarding disparam no vazio, arrastando a conversão de período de teste para pago. Email transacional — redefinições de senha, recibos, códigos de dois fatores — nunca chega, gerando tickets de suporte a US$ 5–15 cada. Campanhas de marketing acumulam rejeições totais que prejudicam sua reputação de remetente em todo o domínio, não apenas para os endereços com erro de digitação. A matriz de custo na próxima seção quantifica cada canal para cinco modelos de negócio comuns.
O Custo Real dos Erros de Digitação de Email Em Cinco Modelos de Negócio
A mesma taxa de 1–3% de erro de digitação produz danos em dólares dramaticamente diferentes dependendo do que o email realmente faz no seu negócio. Um lead B2B com erro de digitação e um checkout de e-commerce com erro de digitação falham de maneiras diferentes, em linhas do tempo diferentes, contra baselines de receita diferentes.
| Modelo de Negócio | Função de Email Principal Perdida | Impacto da Taxa de Erro de Digitação | Efeito Composto |
|---|---|---|---|
| Período de teste do SaaS | Ativação + sequência de onboarding | 1–2% nunca iniciam período de teste | 15–25% de ganho de onboarding perdido |
| Checkout de e-commerce | Confirmação de pedido + envio | 1–3% disparam tickets de suporte | US$ 5–15 por "onde está meu pedido" |
| Newsletter / conteúdo | Boas-vindas + campanhas contínuas | 1–3% nunca confirmam engajamento | Rejeição aproxima-se da zona de perigo de 2% |
| Geração de lead B2B | Nutrição de lead + passagem de vendas | 0,5–1,5% (pesado em desktop) | MQL perdido = CAC inteiro desperdiçado |
| Aplicativo de consumidor focado em dispositivo móvel | Verificação de conta + re-engajamento | 2–3%+ (inclinação móvel) | Compõe retenção móvel baixa |
Fontes de taxa de erro de digitação: análise de 4 bilhões de endereços da ZeroBounce e pesquisa de domínio com erro de digitação da Kickbox. Números de ganho de onboarding do Totango 2023 SaaS Metrics Report. Limites de rejeição do benchmarks de entregabilidade da Mailchimp e M3AAWG Sender Best Common Practices. Taxas de erro móvel da pesquisa de entrada de texto do MobileHCI de Azenkot e Zhai.
SaaS sofre o maior impacto em dólares por erro de digitação porque o custo se compõe ao longo de todo o ciclo de vida do cliente. Faça as contas. Os benchmarks da Totango colocam o ganho de uma sequência de email de onboarding estruturada em 15–25% acima de nenhuma sequência. Um usuário com erro de digitação recebe zero emails de onboarding e reverte à conversão de baseline. Para um plano de US$ 50/mês com tenure média de 12 meses, um delta de conversão de 20 pontos em cada usuário perdido representa aproximadamente US$ 120 em receita esperada por inscrição com erro de digitação. Com 10.000 inscrições por mês e uma taxa de 1,5% de erro de digitação, são 150 usuários × US$ 120 = aproximadamente US$ 18.000 por mês em receita esperada silenciosamente perdida — antes de contar efeitos de referência, expansão ou boca a boca.
Cada ponto percentual de erros de digitação não detectados no seu formulário de inscrição é um ponto percentual do seu investimento em onboarding que dispara no vazio.
E-commerce paga em carga de suporte, não apenas email perdido. Os dados de benchmark de atendimento ao cliente da Zendesk colocam problemas de autenticação e "Não recebi meu email" entre as principais categorias de tickets de entrada, frequentemente representando 15–30% do volume total. Uma parte significativa remonta à captura com erro de digitação, não falha de entregabilidade no lado do remetente. O cliente digitou gmial.com, a confirmação de pedido teve rejeição total, o cliente assume que o pedido falhou, e o ticket vai para a fila a US$ 5–15 para resolver manualmente.
Os remetentes de newsletter enfrentam cascatas de reputação. Quando 1–3% das novas inscrições sofrem rejeição total, você acelera em direção ao teto de rejeição por campanha que a Mailchimp sinaliza como zona de perigo de entregabilidade. O dano não é isolado para os endereços com erro de digitação — os ISPs aplicam filtragem ao seu domínio de envio inteiro uma vez que as taxas de rejeição sustentam acima de 2%. Uma cohorte de captura ruim pode suprimir o posicionamento legítimo em caixa de entrada para as próximas três campanhas.
O ROI de email relatado pela DMA de US$ 35–US$ 42 por cada US$ 1 gasto (DMA Marketer Email Tracker) amplifica o cálculo de custo. Até pequenas porcentagens de emails não entregues se multiplicam contra essa taxa de alavancagem. Uma taxa de erro de digitação de 1,5% não é perda de receita de 1,5% — é 1,5% do seu investimento em envio produzindo zero resultado enquanto os 98,5% restantes produzem o ROI publicado. A assimetria é o que torna os erros de digitação particularmente dignos de correção em relação ao seu tamanho aparente.
Os Seis Padrões de Erros de Digitação Que Explicam a Maioria dos Endereços Ruins
Erros de digitação não são aleatórios. Eles se agrupam em um punhado de padrões mecânicos impulsionados pelo layout de teclado, comportamento de autocorreção móvel e atalhos cognitivos previsíveis. Conhecer o mecanismo por trás de cada padrão diz a você o que é deterministicamente corrigível versus o que precisa de confirmação do usuário.
- Erros de digitação de proximidade em nível de domínio (gmial, yhoo, hotnail). Estes seguem adjacência de teclado QWERTY — "i" e "a" sentam-se um ao lado do outro na linha inicial, o dedo do índice escorrega, o formulário aceita o resultado. A ZeroBounce identifica estes como a única maior categoria de erro de digitação em seu conjunto de dados de 4 bilhões de endereços. Eles também são os mais recuperáveis: a distância de Levenshtein para o domínio correto é 1, correspondência difusa contra uma lista curta de provedores principais os detecta com alta precisão.
- Confusão de TLD (.co vs .com, .net vs .com, .om vs .com). Impulsionada por teclados móveis onde ".com" é uma única tecla de atalho que pode ser perdida, e por usuários em mercados com TLDs de código de país ativos (.co.uk, .com.au) que se lembram por memória muscular em uma combinação errada. Particularmente prejudicial porque ".co" é em si um TLD válido atribuído à Colômbia. Verificações de existência de domínio passam limpamente. A caixa de correio quase com certeza não existe.
- Trocas de subdomínio e provedor (outlook.com ↔ live.com, icloud ↔ icould, msn ↔ mns). Usuários se lembram erroneamente qual domínio Microsoft ou da era Apple sua conta usa, especialmente após migrações. Maior prevalência em demografias de usuários mais antigas onde a inscrição original aconteceu em um provedor legado. Correspondência difusa contra um registro de domínio com erro de digitação as detecta; regex não.
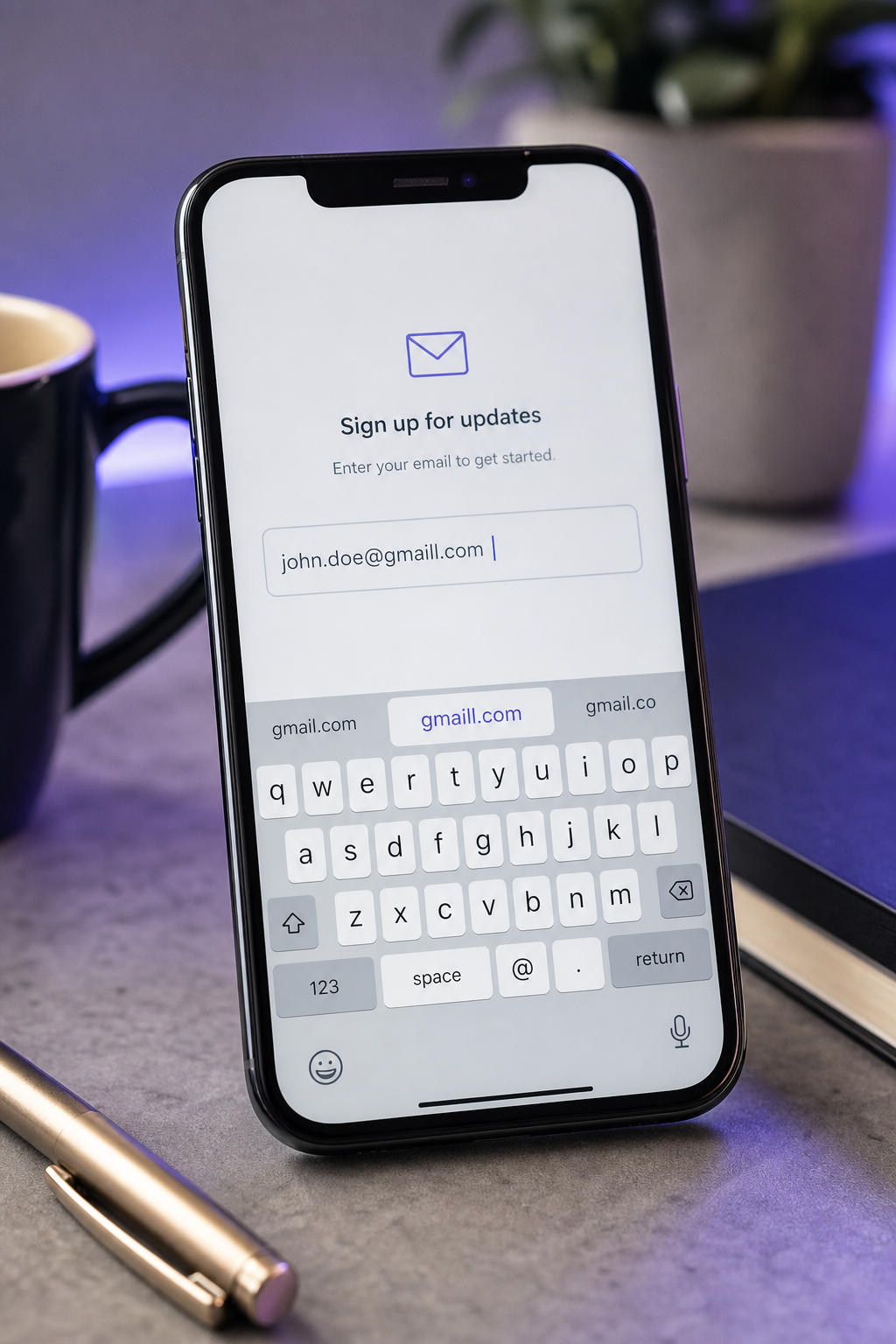
- Caracteres duplicados ou descartados (aaccount, coom, gmaill, hotmai). Artefatos de preenchimento automático de tela sensível ao toque. A pesquisa de entrada de texto de Azenkot e Zhai documenta sistematicamente taxas de erro de caractere mais altas em telas sensíveis ao toque do que em teclados de hardware, particularmente para strings que os usuários não revisam visualmente antes de enviar. Campos de email são de alto risco porque são longos, não-dicionário e visualmente densos.
- Autocorreção móvel override. O texto preditivo silenciosamente "corrige" fragmentos de email válidos em palavras de dicionário comuns ("gmail" → "gail", "outlook" → "outlooks"). A correção é estrutural em vez de detectiva: campos de entrada devem declarar
type="email"eautocomplete="email"para desabilitar autocorreção no nível do SO. A orientação de design de formulário do Nielsen Norman Group trata isto como prática de baseline para qualquer campo de alto risco de erro. - Escorregadas de espaço em branco e pontuação (espaço final, vírgula-por-ponto, @ duplicado). Frequentemente invisível para o usuário porque o campo de formulário visualmente aparenta a exibição, ocultando o problema até SMTP rejeitar o endereço. A lógica de strip-and-normalize na captura elimina o subconjunto recuperável; o resto precisa de validação explícita contra a gramática de endereço.
Desses seis padrões, três são deterministicamente corrigíveis a partir da string de endereço sozinho (proximidade, TLD, caracteres duplicados), dois requerem confirmação do usuário porque são ambíguos (trocas de subdomínio, autocorreção overrides), e um é pré-empted na camada de entrada antes de qualquer validação executar (espaço em branco). O mapa de remediação importa porque define o contrato UX: quais padrões justificam normalização silenciosa, quais justificam um prompt "Você quis dizer?", e quais justificam bloquear com uma mensagem de erro.
Métodos de Detecção Comparados — O Que Realmente Detecta Erros de Digitação na Captura
A maioria das equipes já tem algo validando seu campo de email. A questão é se o que têm realmente detecta a categoria de erro de digitação em oposição à categoria de sintaxe. Os cinco métodos abaixo cobrem o espaço de opção realista.
| Método | Detecta Erros de Digitação | Tempo Real | Atrito Adicionado | Impacto da Lista |
|---|---|---|---|---|
| Verificação de sintaxe Regex / RFC | Não | Sim | Nenhum | Nenhum |
| Confirmação de double opt-in | Após rejeição | Não (assíncrono) | Alto | 20–40% encolhimento |
| Correspondência difusa do lado do cliente | Parcial | Sim | Baixo | Mínimo |
| Verificação de registro MX de domínio | Não | Sim | Nenhum | Baixo |
| API de verificação em tempo real | Sim | Sim (sub-500ms) | Mínimo | Mínimo |
Número de encolhimento de double opt-in: estudo de single-vs-double opt-in da GetResponse. Latência de API em tempo real: documentação de API da NeverBounce. Arquitetura de validação de três camadas (sintaxe → MX → caixa de correio): documentação de API da ZeroBounce.
Regex é necessário mas insuficiente. Ele força RFC 5321 e 5322 limpar, filtra strings obviamente malformadas, e executa em tempo zero no cliente. Cada endereço com erro de digitação discutido anteriormente passa regex sem piscar. Trate regex como seu primeiro filtro, nunca como único.
Double opt-in é a "solução" mais popular e a mais cara. O estudo da GetResponse descobriu que listas de double opt-in eram 20–40% menores do que listas de single opt-in — e os usuários com erros de digitação são matematicamente garantidos de estar no 20–40% perdido porque não conseguem receber o email de confirmação por definição. O mecanismo é de cabeça para baixo: emails de confirmação diagnosticam o problema de erro de digitação apenas após o usuário já estar perdido. Você descobre sobre o erro de digitação quando a própria mensagem de confirmação sofre rejeição total, momento em que o usuário fechou a aba. Double opt-in ainda tem valor para filtragem de permissão e engajamento. Não é, em nenhum sentido significativo, uma camada de detecção de erro de digitação.

Correspondência difusa do lado do cliente ("Você quis dizer gmail.com?") é uma boa UX, frágil como infraestrutura. Exige manter um dicionário de domínio com erro de digitação, lidar com domínios internacionalizados, e evitar o modo de falha documentado pelo Baymard Institute no qual TLDs legítimos de código de país ou corporativo são sinalizados como erros de digitação. O dicionário envelhece. Novos padrões de erro de digitação emergem. Útil como uma camada de UI em cima de uma chamada de verificação real. Não é um substituto para uma.
Verificações de registro MX descartam domínios inexistentes mas perdem casos de erro de digitação de domínio real. "gmial.com" é um domínio registrado e resolvendo MX — é exatamente por isso que é uma armadilha de erro de digitação de longo prazo. O squatter quer o tráfego. Verificações MX detectam domínios fabricados; não detectam a categoria de erro de digitação deste artigo. A verificação é barata e vale a pena executar, mas não confunda passar com ser um endereço real.
APIs de verificação em tempo real combinam todas as quatro camadas. A arquitetura padrão documentada pela ZeroBounce e NeverBounce executa sintaxe → MX → sonda de nível de caixa de correio → bandeira de domínio com erro de digitação → bandeira de domínio descartável em uma única chamada sub-500ms. A saída não é um passe/falha binário; é um veredito classificado no qual o fluxo de registro pode ramificar diferentemente por categoria. Uma chamada de validação de endereço de email em tempo real retorna esses sinais como códigos de resultado separados, que é o que permite sugerir para erros de digitação, bloquear para descartáveis, e rejeitar para inválidos sem escrever cinco validadores independentes.
Latência não é uma objeção. Os tempos de resposta publicados da NeverBounce de 100–500ms estão abaixo do limiar perceptual para lag de UI, especialmente quando a chamada dispara no desfoque de campo em vez do envio. Os usuários já moveram sua atenção para o próximo campo; a sugestão aparece quando eles olham novamente.
Um Fluxo de Registro Resistente a Erros de Digitação Em Sete Decisões
A arquitetura abaixo é tática, não teórica. Cada item é uma decisão que a equipe faz uma vez e codifica no caminho de código de registro. A lógica importa mais do que a sintaxe específica — adapte para sua stack.
- Valide no desfoque, não apenas no envio. Execute a chamada de verificação quando o campo de email perde foco para que o prompt de sugestão apareça antes de o usuário ter se comprometido mentalmente com o próximo campo. A pesquisa de formulário do Nielsen Norman Group mostra que validação inline supera validação em tempo de envio para recuperação de erro porque o usuário ainda está orientado para o campo que acabou de deixar. Erros em tempo de envio requerem re-orientação e parecem punição.
- Use uma resposta de API classificada por veredito, não booleana. A resposta deve separar bandeiras de erro de digitação, descartável, conta de função, e caixa de correio inválida para que cada uma possa disparar UI diferente. Respostas "is_valid" booleanas forçam você a escolher um tratamento para cinco problemas diferentes, que é como equipes terminam bloqueando usuários recuperáveis. APIs de fornecedor estruturam respostas desta forma por uma razão.
- Sugira, não auto-corrija. Para bandeiras de erro de digitação, renderize "Você quis dizer [email protected]?" como uma aceitação de um clique. Auto-correção silenciosa viola confiança do usuário — a pesquisa de formulário de e-commerce do Baymard mostra usuários abandonam quando detectam um campo mudando sob eles — e quebra para casos legítimos de borda como domínios corporativos que parecem erros de digitação mas não são.
- Bloqueie descartáveis separadamente de erro de digitação. Um sinal descartável justifica um bloqueio total ou redução para uma conta de nível convidado com recursos limitados. Um sinal de erro de digitação justifica uma sugestão suave com uma correção de um clique. Tratar ambos igualmente penaliza usuários recuperáveis enquanto sob-protege contra abuso de período de teste. O custo de ramificação é um condicional extra.
- Desabilite autocorreção na camada de entrada. Use
<input type="email" autocomplete="email" autocorrect="off" spellcheck="false">. Isto pre-empta o padrão de autocorreção override antes de qualquer validação executar. É uma mudança de cinco atributos que elimina uma classe inteira de erro de digitação. - Defina limites de rejeição total e instrumente-os. Tanto M3AAWG quanto Mailchimp aconselham que rejeições totais agregadas fiquem abaixo de 1% por campanha, com 2% sendo a zona de perigo de entregabilidade. Alerte em taxas de rejeição de cohort de inscrição acima de 1,5% — não apenas em taxas de campanha-wide. A rejeição em nível de cohort é um indicador leading de que sua validação do lado de captura está falhando para uma fonte específica, que as médias de campanha-wide diluirão.
- Registre padrões de erro de digitação e retroalimente-os. Rastreie quais domínios seus usuários mais frequentemente digitam com erro. Se seu público produz um padrão recorrente de "yaho.com" ou ".cm", você agora sabe onde enrijecer a lógica de sugestão. Isto fecha o loop entre detecção em tempo de captura e insight contínuo de higiene de lista — e permite medir o delta real de cada mudança de validação em vez de adivinhar.

O fluxo como um todo leva uma integração de API e um punhado de decisões de UI. O pagamento se compondo é que cada sistema a jusante — onboarding, cobrança, suporte, marketing — opera em endereços que já limparam os filtros de erro de digitação, descartável, e inválido no limite. Você para de diagnosticar problemas de qualidade de lista em dashboards e começa a preveni-los no formulário.
O Que Os Praticantes Realmente Perguntam Sobre Erros de Digitação de Email
- Um email de confirmação não está já detectando os erros de digitação? Não — diagnostica, não detecta. A comparação de single-vs-double opt-in da GetResponse descobriu que 20–40% dos usuários nunca confirmam, e os usuários com erros de digitação são matematicamente garantidos de estar no grupo faltante porque não conseguem receber a confirmação por definição. Você aprende sobre o erro de digitação apenas quando a própria mensagem de confirmação sofre rejeição total, momento em que o usuário fechou a aba e seguiu adiante. Validação de endereço de email em tempo real do lado de captura superficializa o erro de digitação enquanto o usuário ainda está no formulário e pode corrigi-lo com um clique. Emails de confirmação permanecem valiosos para filtragem de permissão e engajamento — provam que o usuário realmente queria receber seu email. Não são, mecanicamente, um substituto para detecção de erro de digitação na captura. As duas camadas fazem trabalhos diferentes e devem coexistir.
- Se eu auto-corrigir "gmial" para "gmail", não estou sobrescrevendo intenção do usuário? Você está corrigindo um erro de entrada mecânico, não uma escolha intencional — mas apenas se confirmar com o usuário. A pesquisa de formulário de e-commerce do Baymard Institute mostra que correções silenciosas danificam confiança e quebram casos de borda, particularmente domínios corporativos e TLDs regionais que parecem erros de digitação mas não são (.co Colômbia, .om Omã). O padrão defensável é uma sugestão de um clique: "Você quis dizer [email protected]? [Sim, usar isto] [Não, manter meu]." Isto preserva agência do usuário enquanto torna a correção sem atrito. O usuário retém a decisão final, o endereço com erro de digitação é recuperado nos 95%+ dos casos onde a sugestão está correta, e o raro caso legítimo de borda tem um caminho de override limpo. Reescritas silenciosas otimizam para a métrica errada e produzem uma experiência pior para a cauda longa.
- Qual é a diferença entre um endereço com erro de digitação e um endereço descartável — e por que importa? Um erro de digitação é um usuário legítimo com um erro mecânico; um descartável é um usuário evitando ativamente um relacionamento. Os sinais se sobrepõem a jusante — ambos produzem rejeições, ambos reduzem qualidade de lista, ambos prejudicam entregabilidade — mas a resposta na captura deve diferir. Erros de digitação recebem um prompt de sugestão porque o usuário quer entrar. Descartáveis são bloqueados ou reduzidos porque o usuário está optando por sair enquanto aparenta optar por entrar. Uma API em tempo real que os sinaliza separadamente permite rotear cada apropriadamente sem escrever dois validadores paralelos. Tratá-los identicamente ou sobre-bloqueia usuários recuperáveis (se você rejeita duramente erros de digitação junto com descartáveis) ou sob-protege contra abuso de período de teste (se você apenas avisa suavemente descartáveis junto com erros de digitação). Um verificador de endereço de email descartável dedicado trata a camada de detecção específica para descartável; uma camada de sugestão de erro de digitação fica em cima dela.
- Quantas das minhas inscrições realmente têm erros de digitação agora? Os dados da indústria convergem em 0,5–2% para públicos B2B pesados em desktop e 2–3%+ para aplicativos de consumidor pesados em dispositivos móveis, com o conjunto de dados de 4 bilhões de endereços da ZeroBounce e pesquisa de domínio com erro de digitação da Kickbox como as duas fontes mais citadas. Para medir sua própria baseline em vez de adivinhar: puxe os últimos 90 dias de inscrições, faça referência cruzada contra o log de rejeição total do seu ESP, e isole as rejeições onde o domínio é um caractere de Levenshtein afastado de um provedor principal (gmail, yahoo, hotmail, outlook, icloud, aol). Esse subconjunto é sua taxa de erro de digitação atual. Execute a mesma consulta novamente 30 dias após implantar validação em tempo real para medir o delta limpamente. Os números antes/depois são os únicos que importam para justificar a integração internamente.
- Posso construir detecção de erro de digitação eu mesmo sem uma API? Parcialmente. Um script de correspondência difusa do lado do cliente contra uma lista codificada de domínios com erro de digitação comuns (gmial.com, yaho.com, hotnail.com, outlok.com, icould.com) detecta 60–70% dos casos de baixo custo — distância de Levenshtein ≤ 2 contra uma lista de 20 provedores principais cobre uma fração surpreendente do volume. Os casos restantes requerem infraestrutura: tratamento de confusão de TLD, detecção de troca de subdomínio, sondas de não-existência de caixa de correio, e um registro de domínio com erro de digitação continuamente atualizado conforme novos padrões emergem. O limiar de construir vs. comprar é geralmente se sua equipe quer possuir manutenção de dicionário, infraestrutura de verificação de MX, e sondas de caixa de correio de SMTP em perpetuidade. Para a maioria das equipes, o caminho de API é mais barato do que a sobrecarga de manutenção, e o ganho de cobertura marginal nos padrões de cauda longa é onde a receita real vive — não nos primeiros 60% que qualquer script decente trata no primeiro dia.