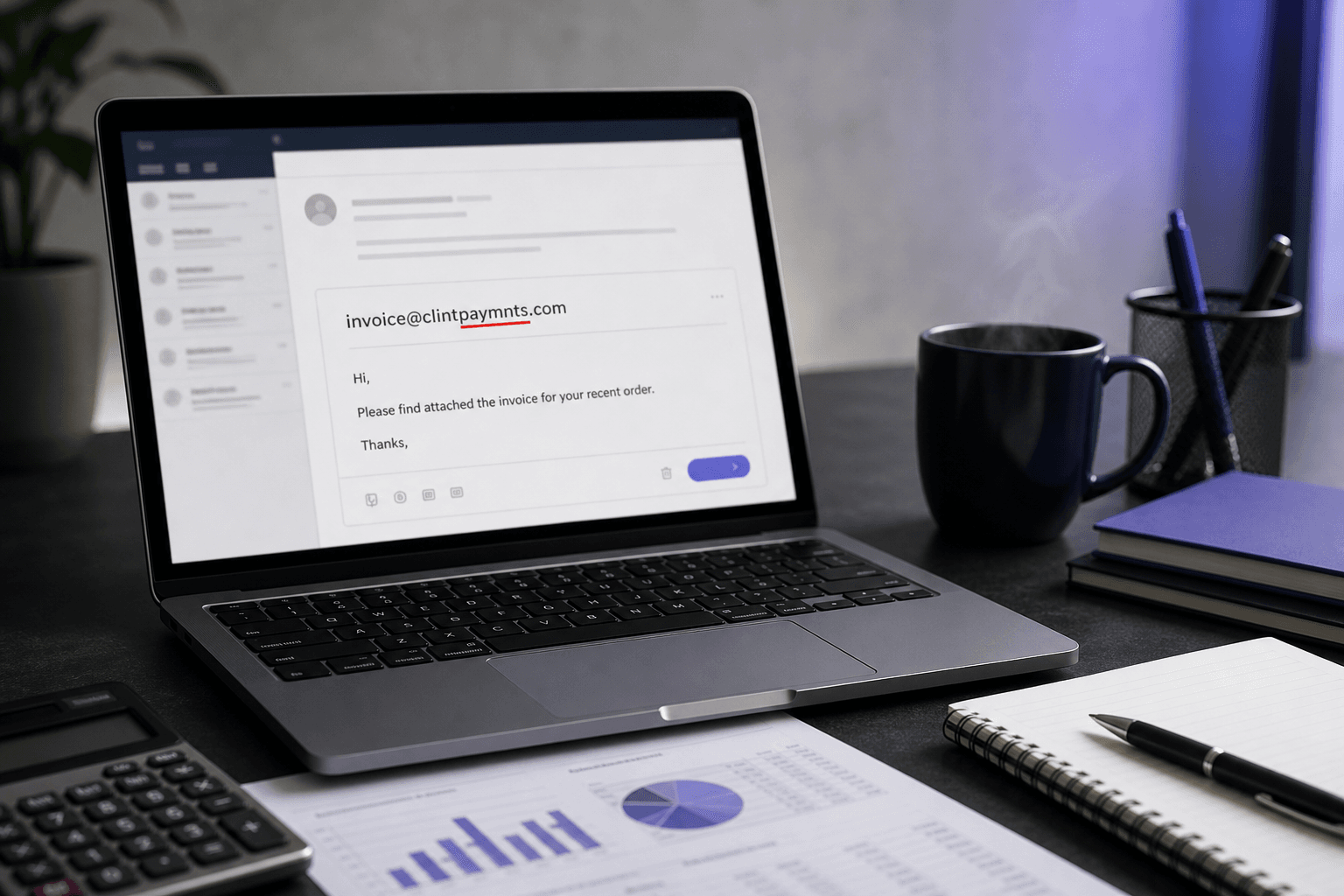
一家SaaS公司的注册表单在周二获得了500个新用户。入门序列在周三上午启动。到了周四,7封邮件已经硬退信——不是来自虚假地址或一次性邮箱,而是来自"gmial.com"、"yaho.com"、"hotmial.com"。这7个用户在手机上快速输入,点击提交,然后继续。他们永远看不到激活邮件。有些会回访,指责产品有问题,然后流失。其余的就此消失。
你的转化漏斗中的每一个邮箱拼写错误都对应一个真实的人,他们想要加入。这不是欺诈。这不是机器人流量。这是每个列表中1-3%的安静声音,根据ZeroBounce对超过40亿个地址的分析,这些邮箱显示为拼写错误的域——地址通过了每一项正则表达式检查,看起来完全有效,但却在第一封入门邮件到达之前悄然破坏了你的漏斗。

目录
- 为什么邮箱拼写错误是一个不同的问题
- 邮箱拼写错误在五种商业模式中的真实成本
- 占大多数错误地址的六种拼写错误模式
- 检测方法对比——在获取时真正捕捉拼写错误的方法
- 七个决策中的抗拼写错误注册流程
- 从业者实际提出的关于邮箱拼写错误的问题
为什么邮箱拼写错误是一个不同的问题
从分类开始,因为本文的其余部分都依赖于它。在每个注册表单中都会出现三种故障模式,它们在你的退信日志中看起来相似,但需要完全不同的应对方式。
拼写错误的地址是指合法用户出现的机械输入错误:gmial.com、yaho.com、hotnail.com、outlok.com。用户想要这个邮箱。他们期望激活链接。他们快速输入,错过了一个字符,表单接受了它。漏斗中的每一个指标都会将他们视为参与度然后消失的用户,而实际上他们是从一开始就无法联系的用户。
一次性邮箱地址在格式上是合法的,但在意图上是有意回避的:mailinator.com、tempmail.io、guerrillamail.com。用户在看似选择加入的同时实际上选择了退出关系。他们想要试用、门控内容、折扣代码——但不想要生命周期消息。专业的一次性邮箱地址检查器处理这个类别,因为检测逻辑本质上是域信誉查找,而不是邻近性计算。
无效或虚假地址是垃圾字符串、虚构的域名或机器人提交:[email protected]、[email protected]。没有人工意图,没有可恢复的信号。拒绝并继续。
这些在注册边界需要不同的处理。一次性邮箱应该被阻止或降级到访客层级。拼写错误应该用一键纠正提示标记。虚假邮箱应该用通用错误拒绝。将它们视为单一的"坏邮箱"类别会导致两种故障模式之一:要么通过硬拒阻给可恢复的用户增加摩擦,要么接受一切并吸收下游的退信损害。两者都很昂贵。
正则表达式验证无法捕捉拼写错误的原因是结构性的,而不是特定实现的。RFC 5321和RFC 5322定义了邮箱地址的语法——允许的字符、引用规则、域格式、长度限制。字符串"[email protected]"完全符合RFC。邮箱不存在;域名注册给了打字错误的抢注者;用户永远不会从你的服务器收到任何东西。但这个字符串是有效的。正则表达式对字符起作用,而不是对DNS解析或域邻近性起作用。这是模式匹配的类别限制,不是你能通过更好的模式修复的东西。
拼写错误的地址完全符合RFC,语法完美,结构上与真实地址无法区分——这正是为什么你的验证层让它通过了。
隐藏的数量比大多数团队估计的要大。ZeroBounce的40亿地址数据集将拼写错误的域放在了典型网络表单获取的1-3%范围内。Kickbox的拼写错误域研究指出,移动设备繁重的受众倾向于该范围的上端,因为触摸屏输入产生的字符级错误率高于物理键盘。对于每月进行10,000次注册、拼写错误率为1.5%的SaaS,这意味着每月有150个用户从你发送的每一封生命周期邮件中自动取消资格——激活、功能教育、账单提醒、赢回。
这150个用户同时流经三个下游成本渠道。入门序列进入虚空,拖累了试用到付费的转换。交易邮件——密码重置、收据、双因素代码——永远无法送达,每张$5-15的支持工单被生成。营销活动累积硬退信,侵蚀了整个域名的发送者声誉,而不仅仅是拼写错误的地址。下一部分的成本矩阵为五种常见商业模式量化了每个渠道。
邮箱拼写错误在五种商业模式中的真实成本
相同的1-3%拼写错误率根据邮箱在你业务中实际所做的事情产生截然不同的美元损害。拼写错误的B2B线索和拼写错误的电子商务结账以不同的方式、在不同的时间表上、针对不同的收入基线而失败。
| 商业模式 | 丧失的主要邮件功能 | 拼写错误率影响 | 复合效应 |
|---|---|---|---|
| SaaS免费试用 | 激活+入门序列 | 1-2%永远不启动试用 | 15-25%入门提升丧失 |
| 电子商务结账 | 订单确认+发货 | 1-3%触发支持工单 | "我的订单在哪里"为$5-15 |
| 新闻通讯/内容 | 欢迎+持续活动 | 1-3%永远不确认参与 | 退信接近2%危险区 |
| B2B线索生成 | 线索培养+销售交接 | 0.5-1.5%(台式机繁重) | 丧失MQL=全部CAC浪费 |
| 移动优先消费者应用 | 账户验证+重新参与 | 2-3%+(移动倾斜) | 加剧低移动设备保留 |
拼写错误率来源:ZeroBounce 40亿地址分析和Kickbox拼写错误域研究。入门提升数据来自Totango 2023 SaaS指标报告。退信阈值来自Mailchimp的可交付性基准和M3AAWG发送者最佳通用实践。移动错误率来自Azenkot和Zhai的MobileHCI文本输入研究。
SaaS受到最高的每拼写错误美元影响,因为成本在整个客户生命周期中复合。让我们详细计算。Totango基准将结构化入门邮件序列的提升放在相比无序列提升15-25%。拼写错误的用户收到零入门邮件并恢复到基线转换。对于$50/月的计划,平均期限为12个月,每个丧失用户的20点转换增量代表大约$120的预期收入。在每月10,000次注册和1.5%拼写错误率下,这是150个用户×$120=大约每月$18,000的预期收入被默默丧失——在计算推荐、扩展或口碑效应之前。
注册表单中每个未检测到的拼写错误百分比都是你的入门投资中进入虚空的百分比。
电子商务用支持负载而不是仅仅丧失的邮件付费。Zendesk的客户服务基准数据将身份验证和"我没有收到邮件"问题列为入站工单的热门类别,频繁占总量的15-30%。有意义的份额追溯到拼写错误捕获,而不是发送方的可交付性故障。客户输入了gmial.com,订单确认硬退信,客户假设订单失败,工单排队等待$5-15的手动解决。
新闻通讯发送者面临声誉级联。当1-3%的新注册硬退信时,你加速趋向Mailchimp标记的每个活动退信上限的可交付性危险区。损害不仅限于拼写错误的地址——一旦退信率持续高于2%,互联网服务提供商对你的整个发送域应用过滤。一个错误的捕获群组可能会对接下来的三个活动抑制合法的收件箱放置。
DMA报告的电子邮件ROI为每$1花费$35-$42(DMA营销人员电子邮件追踪器)放大了成本计算。即使很小的未交付邮件百分比也会乘以该杠杆比率。1.5%的拼写错误率不是1.5%的收入损失——这是1.5%的你的发送投资产生零输出,而剩余98.5%产生发布的ROI。不对称性就是为什么拼写错误相对于其表观大小特别值得修复。
占大多数错误地址的六种拼写错误模式
拼写错误不是随机的。它们聚集成少数由键盘布局、移动自动更正行为和可预见的认知捷径驱动的机械模式。了解每个模式背后的机制会告诉你什么是决定性可纠正的,相对什么需要用户确认。
- 域级邻近拼写错误(gmial、yhoo、hotnail)。这些遵循QWERTY键盘邻近性——"i"和"a"在主行上彼此相邻,索引手指滑动,表单接受结果。ZeroBounce在其40亿地址数据集中将这些确定为单一最大的拼写错误类别。它们也是最可恢复的:正确域的Levenshtein距离为1,对主要提供商短列表的模糊匹配以高精度捕捉它们。
- TLD混淆(.co vs .com、.net vs .com、.om vs .com)。由移动键盘驱动,其中".com"是单个快捷键可能被错过的,也由活跃的国家代码TLD市场中的用户驱动,他们肌肉记忆了错误的组合。特别有害,因为".co"本身是分配给哥伦比亚的有效TLD。域存在性检查完全通过。邮箱几乎肯定不存在。
- 子域和提供商交换(outlook.com ↔ live.com、icloud ↔ icould、msn ↔ mns)。用户误记了他们的账户使用的是Microsoft或Apple时代的哪个域,特别是在迁移之后。在原始注册发生在遗留提供商的较老用户人口中有更高的流行率。对拼写错误域注册表的模糊匹配会捕捉这些;正则表达式不会。
- 重复或删除的字符(aaccount、coom、gmaill、hotmai)。触摸屏自动填充伪影。Azenkot和Zhai的文本输入研究在触摸屏上记录了系统性更高的字符级错误率,特别是对于用户在提交前不目视检查的字符串。电子邮件字段是高风险的,因为它们很长、非字典且视觉密集。
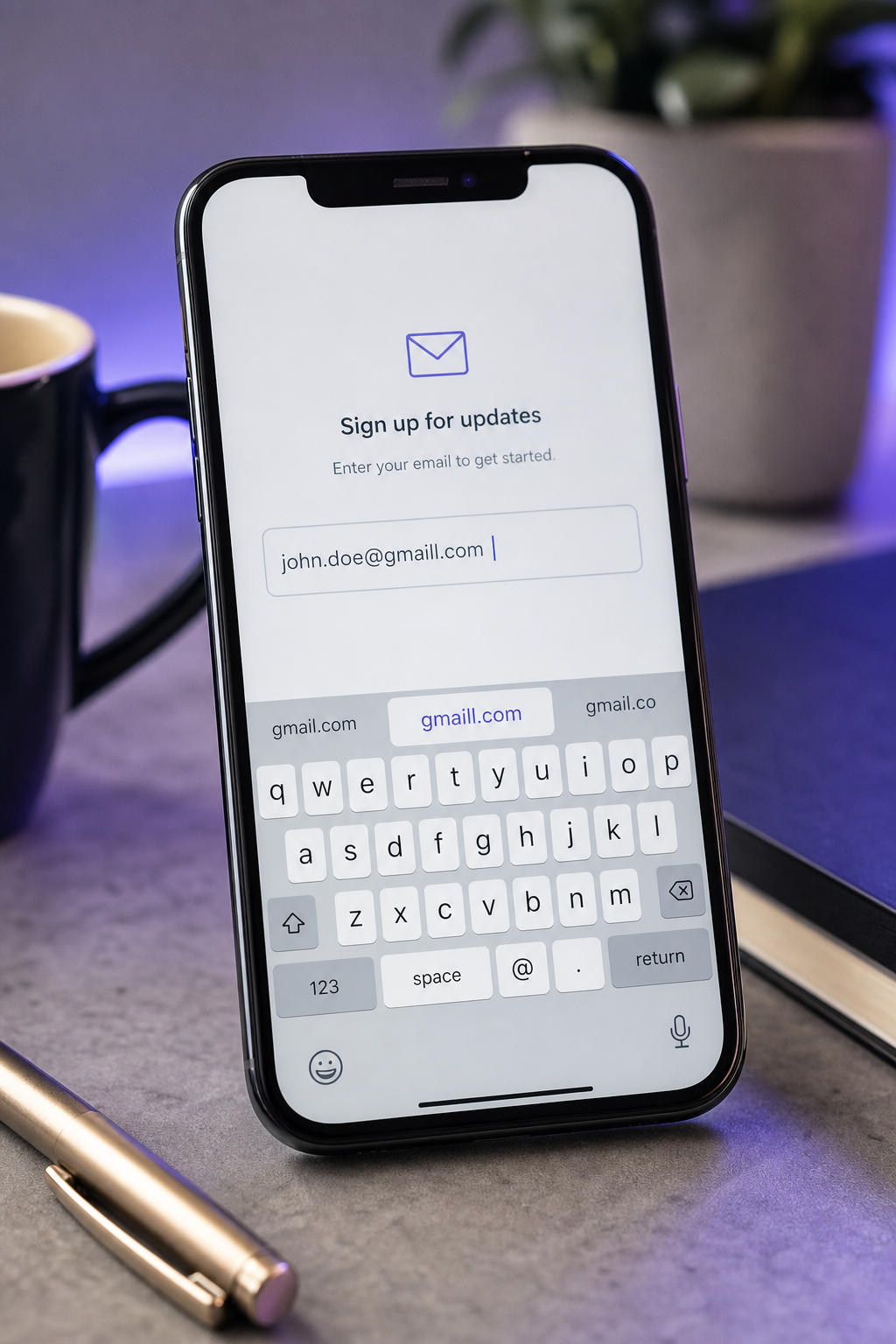
- 移动自动更正覆盖。预测文本悄然"更正"有效的邮件片段为常见字典词("gmail"→"gail"、"outlook"→"outlooks")。修复是结构性的而不是侦查性的:输入字段应该声明
type="email"和autocomplete="email"来在操作系统级别禁用自动更正。Nielsen Norman Group的表单设计指南将其视为任何高风险错误字段的基准实践。 - 空白和标点符号滑动(尾随空格、逗号代替句号、重复@)。通常对用户不可见,因为表单字段在视觉上修剪显示,隐藏问题直到SMTP拒绝地址。在捕获时剥离和规范化逻辑消除可恢复的子集;其余的需要对地址语法进行显式验证。
在这六个模式中,三个可以单独从地址字符串确定性地纠正(邻近性、TLD、重复字符),两个需要用户确认,因为它们是模糊的(子域交换、自动更正覆盖),一个在任何验证运行之前在输入层被预防(空白)。补救映射很重要,因为它设置了用户体验契约:哪些模式值得无声规范化,哪些值得"你是说?"提示,哪些值得用错误消息阻止。
检测方法对比——在获取时真正捕捉拼写错误的方法
大多数团队已经有某些验证他们的邮箱字段。问题是他们有的是否真正捕捉拼写错误类别,相对于语法类别。下面的五种方法涵盖了实际的选项空间。
| 方法 | 捕捉拼写错误 | 实时 | 增加的摩擦 | 列表影响 |
|---|---|---|---|---|
| 正则表达式/RFC语法检查 | 否 | 是 | 无 | 无 |
| 双重选择加入确认 | 退信后 | 否(异步) | 高 | 20-40%收缩 |
| 客户端模糊匹配 | 部分 | 是 | 低 | 最少 |
| 域MX记录检查 | 否 | 是 | 无 | 低 |
| 实时验证API | 是 | 是(低于500毫秒) | 最少 | 最少 |
双重选择加入收缩数据:GetResponse单比双选择加入研究。实时API延迟:NeverBounce API文档。三层验证架构(语法→MX→邮箱):ZeroBounce API文档。
正则表达式是必要的但不充分的。它干净地实施RFC 5321和5322,筛选出明显格式错误的字符串,并在客户端零时间运行。前面讨论的每个拼写错误地址都毫不犹豫地通过正则表达式。将正则表达式视为你的第一个过滤器,永远不要作为唯一的过滤器。
双重选择加入是最受欢迎的"解决方案"和最昂贵的。GetResponse的研究发现双重选择加入列表比单一选择加入列表小20-40%——拼写错误的用户在数学上必然在丧失的20-40%中,因为根据定义他们无法收到确认邮件。机制是颠倒的:确认邮件仅在用户已经丧失后诊断拼写错误。你发现拼写错误是在确认消息本身硬退信时,此时用户已经关闭了标签。双重选择加入仍然对权限和参与度过滤有价值。它在任何有意义的意义上都不是拼写错误检测层。

客户端模糊匹配("你是说gmail.com?")是好的用户体验,在基础设施上是脆弱的。它需要维护拼写错误域字典、处理国际化域和避免Baymard Institute记录的故障模式,其中合法的国家代码或公司TLD被标记为拼写错误。字典老化。新的拼写错误模式出现。作为真实验证调用之上的用户界面层有用。不是替代品。
MX记录检查排除不存在的域,但错过了实域的拼写错误案例。"gmial.com"是一个注册的、MX-解析的域——这正是为什么它是一个长期运行的拼写错误陷阱。抢注者想要流量。MX检查捕捉虚构的域;它们不捕捉本文讨论的拼写错误类别。检查便宜且值得运行,但不要误将通过它当作是真实地址。
实时验证API结合了所有四层。ZeroBounce和NeverBounce记录的标准架构在单个低于500毫秒的调用中运行语法→MX→邮箱级探测→拼写错误域标志→一次性域标志。输出不是二进制通过/失败;这是一个分类的裁决,注册流可以针对不同的类别不同地分支。真实邮箱地址验证调用将这些信号作为单独的结果代码返回,这就是让你为拼写错误建议、为一次性邮箱阻止、为无效邮箱拒绝而无需编写五个独立验证器的东西。
延迟不是异议。NeverBounce发布的100-500毫秒的响应时间低于用户界面滞后的感知阈值,尤其是当调用在字段模糊时触发时。用户已经将他们的注意力转向下一个字段;建议在他们回头看时出现。
七个决策中的抗拼写错误注册流程
下面的架构是战术性的,而不是理论性的。每一项都是团队做一次并编入注册代码路径的决策。推理比具体语法更重要——适应你的堆栈。
- 在模糊上验证,不仅在提交时。当邮箱字段失去焦点时运行验证调用,以便建议提示在用户精神上承诺下一个字段之前出现。Nielsen Norman Group的表单研究显示内联验证优于提交时验证以进行错误恢复,因为用户仍然朝向他们刚刚离开的字段。提交时错误需要重新定向并感觉像是惩罚。
- 使用裁决分类的API响应,而不是布尔值。响应应该分离拼写错误、一次性邮箱、角色账户和无效邮箱标志,以便每个都可以触发不同的用户界面。布尔"is_valid"响应强制你为五个不同的问题选择一个处理方式,这就是团队最终阻止可恢复用户的方式。供应商API以这种方式结构化响应是有原因的。
- 建议,不要自动纠正。对于拼写错误标志,将"你是说[email protected]?"呈现为一键接受。无声自动纠正违反用户信任——Baymard的电子商务表单研究显示用户在捕捉字段在他们下方更改时会放弃——它对合法边界情况(如看起来像拼写错误但不是的公司域)中断。
- 将一次性邮箱与拼写错误分开阻止。一次性邮箱信号值得硬阻止或降级到有限功能的访客层级账户。拼写错误信号值得软建议,附加一键修复。以相同方式对待两者在惩罚可恢复用户的同时不足以保护试用滥用。分支成本是一个额外的条件。
- 在输入层禁用自动更正。使用
<input type="email" autocomplete="email" autocorrect="off" spellcheck="false">。这在任何验证运行之前预防自动更正覆盖模式。这是五属性更改消除整个拼写错误类别。 - 设置硬退信阈值并为其装备监听。M3AAWG和Mailchimp都建议每个活动聚合硬退信保持在1%以下,2%是可交付性危险区。在注册群组退信率超过1.5%时发出警报——不仅仅是活动范围的费率。群组级退信是领先指标,表明你的捕获边验证对特定来源失败,活动范围平均将稀释。
- 记录拼写错误模式并反馈。追踪你的用户最频繁拼写错误的域。如果你的受众产生重复的"yaho.com"或".cm"模式,你现在知道在哪里强化建议逻辑。这关闭了捕获时检测和持续列表卫生洞察之间的循环——它让你测量每个验证变化的实际增量,而不是猜测。

流程作为一个整体采用一个API集成和少数用户界面决策。复合回报是每个下游系统——入门、账单、支持、营销——在已经清除了边界处拼写错误、一次性邮箱和无效过滤的地址上运行。你停止在仪表板中诊断列表质量问题,开始在表单处防止它们。
从业者实际提出的关于邮箱拼写错误的问题
- 确认邮件不是已经在捕捉拼写错误了吗?不——它诊断了,它不捕捉它们。GetResponse的单比双选择加入比较发现20-40%的用户永远不确认,拼写错误的用户在数学上必然在缺失的20-40%中,因为根据定义他们无法收到确认。你发现拼写错误是在确认消息本身硬退信时,此时用户已经关闭了标签并继续。实时捕获边邮箱地址验证在用户仍在表单上时表面拼写错误,他们可以用一键纠正。确认邮件仍然对权限和参与度过滤有价值——它们证明用户实际上想要接收你的邮件。它们在机械上不是拼写错误检测捕获的替代品。两个层应该共存和做不同的工作。
- 如果我自动纠正"gmial"为"gmail",我是否在覆盖用户意图?你在纠正机械输入错误,而不是有意选择——但仅当你向用户确认时。Baymard Institute的电子商务表单研究显示无声纠正损害信任并中断边界情况,特别是看起来像拼写错误但不是的公司域和地区TLD(.co哥伦比亚、.om阿曼)。可防守的模式是一键建议:"你是说[email protected]?[是,使用这个][否,保留我的]"。这在做纠正无摩擦的同时保留用户代理。用户保留最终决策,拼写错误的地址在建议是正确的95%+的情况下被恢复,罕见的合法边界情况有干净的覆盖路径。无声重写优化了错误的指标并为长尾产生更差的体验。
- 拼写错误地址和一次性邮箱地址之间的区别是什么——为什么它重要?拼写错误是具有机械错误的合法用户;一次性邮箱是主动回避关系的用户。信号在下游重叠——两者都产生退信,两者都降低列表质量,两者都伤害可交付性——但在捕获的响应应该不同。拼写错误得到建议提示,因为用户想要加入。一次性邮箱被阻止或降级,因为用户在看似选择加入的同时实际选择退出。允许分别标记它们的实时API让你路由每个适当而无需编写两个平行验证器。以相同方式对待它们要么过度阻止可恢复用户(如果你硬拒拼写错误连同一次性邮箱)要么不足以保护试用滥用(如果你仅软警告一次性邮箱连同拼写错误)。专业的一次性邮箱地址检查器处理一次性邮箱特定检测层;拼写错误建议层坐在它之上。
- 我的注册中现在有多少拼写错误?行业数据汇聚到台式机繁重B2B受众的0.5-2%和移动优先消费者应用的2-3%+,ZeroBounce的40亿地址数据集和Kickbox的拼写错误域研究作为两个最被引用的来源。测量你自己的基线而不是猜测:提取最后90天的注册,交叉引用你的ESP的硬退信日志,隔离退信其中域是一个Levenshtein字符关闭主要提供商(gmail、yahoo、hotmail、outlook、icloud、aol)的那些。子集是你的当前拼写错误率。部署实时验证30天后再运行相同查询以干净地测量增量。前后数字是唯一对在内部证明集成有意义的。
- 我能否在没有API的情况下自己构建拼写错误检测?部分地。对常见拼写错误域硬编码列表的客户端模糊匹配脚本(gmial.com、yaho.com、hotnail.com、outlok.com、icould.com)以低成本捕捉案例的顶部60-70%——Levenshtein距离≤2对20个主要提供商列表覆盖令人惊讶的音量份额。剩余案例需要基础设施:TLD混淆处理、子域交换检测、邮箱级非存在探测和作为新模式出现时的持续更新拼写错误域注册表。构建对购买阈值通常是你的团队是否想拥有字典维护、MX检查基础设施和SMTP级邮箱探测永久。对大多数团队,API路径比维护开销便宜,长尾模式上的边际覆盖增益是实际收入所在——不在任何体面脚本在第一天处理的顶部60%。